라이브러리 설치
FinanceDataReader: 주식, 채권, 외환 및 암호화폐와 같은 금융 데이터를 쉽게 불러올 수 있도록 도와주는 파이썬 라이브러리
Plotly: 데이터 시각화를 위한 파이썬 라이브러리로, 인터랙티브한 그래프를 만들 수 있도록 지원
BeautifulSoup4: HTML 및 XML 문서를 파싱하고, 데이터를 추출
Code21
# FinanceDataReader 라이브러리를 불러옵니다.
import FinanceDataReader as fdr
import numpy as np
from matplotlib import pyplot as plt
# 삼성전자(005930)의 주가 데이터를 2016년 1월 1일부터 2020년 12월 23일까지 불러옵니다.
samsung = fdr.DataReader(symbol='005930', start='01/01/2016', end='12/23/2020')
print(samsung) # 불러온 데이터 출력
print(samsung.shape) # 데이터의 형태(행, 열) 출력
print(samsung.columns) # 데이터의 열 이름 출력
# 'Open' 열(시가)만 출력합니다.
print(samsung[['Open']])
# 'Open' 열 데이터를 변수에 저장합니다.
open_values = samsung[['Open']]
print('-' * 50)
print(open_values) # 시가 데이터 출력
print(open_values.shape) # 시가 데이터의 형태 출력
# 최신 데이터를 불러오기 위해 종료일을 None으로 설정하여 현재까지의 데이터를 가져옵니다.
samsung = fdr.DataReader(symbol='005930', start='01/01/2016', end=None)
print(samsung) # 최신 데이터 출력
print(samsung.shape) # 데이터의 형태 출력
print(samsung.columns) # 데이터의 열 이름 출력
print(samsung[['Open']]) # 'Open' 열 출력
# 'Open' 열 데이터를 변수에 저장합니다.
open_values = samsung[['Open']]
print('-' * 50)
print(open_values) # 시가 데이터 출력
print(open_values.shape) # 시가 데이터의 형태 출력
# 데이터 정규화를 위해 MinMaxScaler를 사용합니다.
from sklearn.preprocessing import MinMaxScaler
# MinMaxScaler 객체를 생성하고, 데이터를 0과 1 사이로 정규화합니다.
scaler = MinMaxScaler(feature_range=(0, 1))
scaled_open_values = scaler.fit_transform(X=open_values)
print('-' * 50) # 구분선 출력
print(scaled_open_values) # 정규화된 시가 데이터 출력
print(scaled_open_values.shape) # 정규화된 데이터의 형태 출력
# 테스트 데이터 크기 설정
TEST_SIZE = 200
# 훈련 데이터와 테스트 데이터를 나눕니다. 테스트 데이터는 마지막 200개입니다.
train_data = scaled_open_values[:-TEST_SIZE]
test_data = scaled_open_values[-TEST_SIZE:]
print('-' * 50) # 구분선 출력
print(train_data) # 훈련 데이터 출력
print(train_data.shape) # 훈련 데이터의 형태 출력 (1914)
print('-' * 50) # 구분선 출력
print(test_data) # 테스트 데이터 출력
print(test_data.shape) # 테스트 데이터의 형태 출력 (200)
# RNN-LSTM 모델을 위한 입력 데이터 형태를 생성하는 함수 정의
def make_feature(open_values, windowing: int) -> tuple:
train = list() # 훈련 데이터 리스트
test = list() # 테스트 데이터 리스트
# 윈도우 크기만큼 데이터를 슬라이딩하여 특징을 생성합니다.
for i in range(len(open_values) - windowing):
train.append(open_values[i: i + windowing])
test.append(open_values[i + windowing])
print(train) # 생성된 훈련 데이터 출력
print(test) # 생성된 테스트 데이터 출력
return np.array(train), np.array(test)
# 훈련 데이터로부터 특징 데이터를 생성합니다.
(X_train, y_train) = make_feature(open_values=train_data, windowing=30)
print(f'X_train : {X_train}') # X_train 출력
print(f'X_train.shape : {X_train.shape}') # X_train 형태 출력
print(f'y_train : {y_train}') # y_train 출력
print(f'y_train.shape : {y_train.shape}') # y_train 형태 출력
# LSTM 모델 구현
import keras
model = keras.models.Sequential(name='LSTM_MODEL') # LSTM 모델 초기화
model.add(keras.Input(shape=(X_train.shape[1], 1), name="INPUT")) # 입력층 정의
# 첫 번째 LSTM 층 추가
model.add(keras.layers.LSTM(units=32, return_sequences=True, activation='tanh', name='LAYER1'))
# 두 번째 LSTM 층 추가
model.add(keras.layers.LSTM(units=16, return_sequences=False, activation='tanh', name='LAYER2'))
# 출력층 추가
model.add(keras.layers.Dense(units=1, activation='sigmoid', name="OUTPUT"))
model.summary() # 모델 요약 정보 출력
# 모델 컴파일
model.compile(loss='mse', optimizer='adam') # 손실 함수와 옵티마이저 설정
# 모델 학습
# model.fit(x=X_train, y=y_train, epochs=100, batch_size=16)
# 모델 저장
# model.save("LSTM_MODEL.keras")
model2 = keras.models.load_model('LSTM_MODEL.keras') # 저장된 모델 로드
(X_test, y_test) = make_feature(open_values=test_data, windowing=30) # 테스트 데이터 특징 생성
predictions = model2.predict(x=X_test) # 예측 수행
print(predictions) # 예측 결과 출력
print(predictions.shape) # 예측 결과의 형태 출력
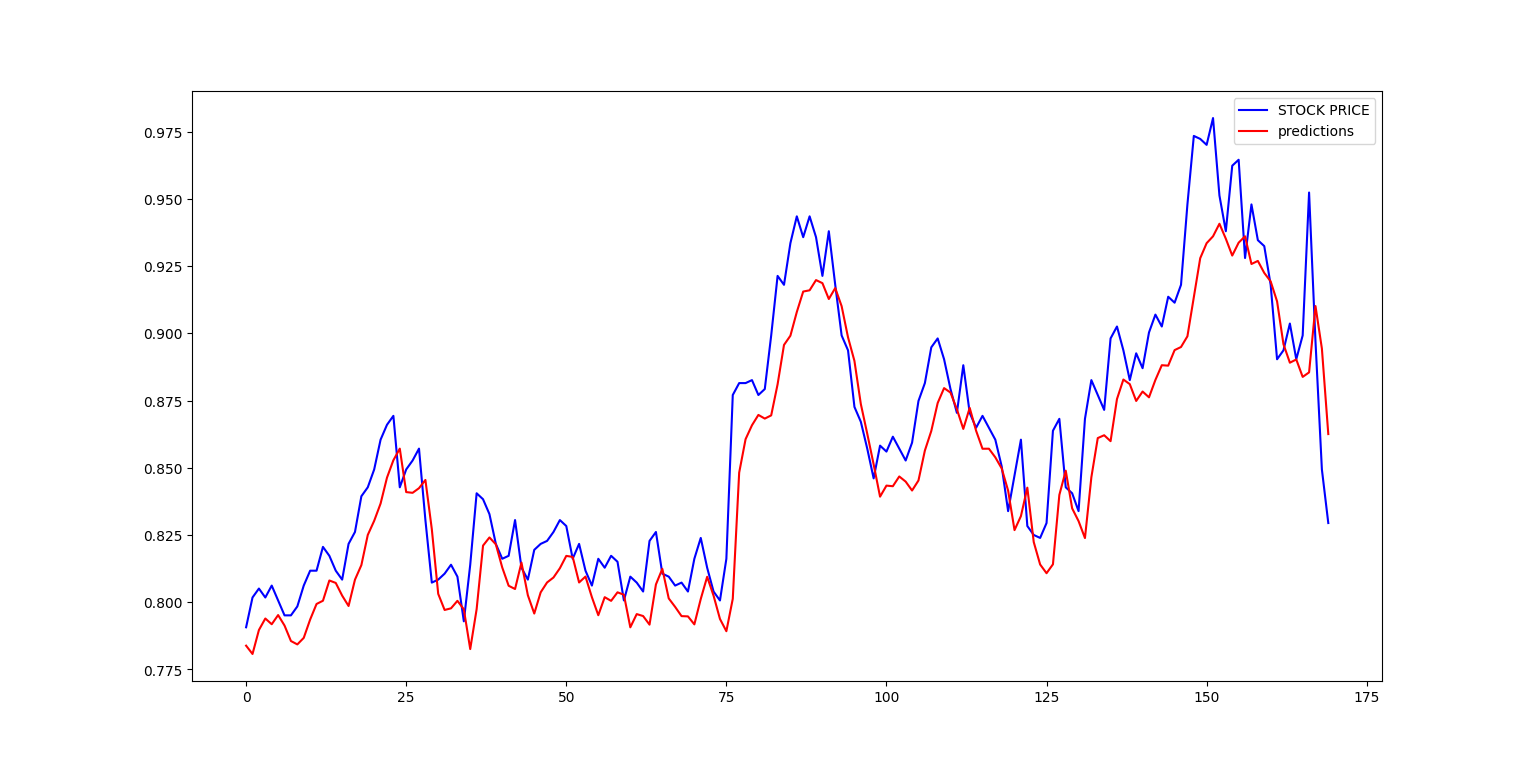
# 예측 결과와 실제 값을 그래프로 시각화
plt.figure(figsize=(10, 8)) # 그래프 크기 설정
plt.plot(y_test, label='STOCK PRICE', color='blue') # 실제 주가 데이터
plt.plot(predictions, label='predictions', color='red') # 예측 결과
plt.legend() # 범례 추가
plt.show() # 그래프 출력코드의 기능 요약
- 데이터 불러오기: 삼성전자 주가 데이터를 특정 기간 동안 불러옵니다.
- 데이터 전처리: 시가 데이터만 추출하고, 정규화하여 값의 범위를 조정합니다.
- 훈련 및 테스트 데이터 분할: 마지막 200개 데이터를 테스트 데이터로 설정하고 나머지를 훈련 데이터로 사용합니다.
- 특징 생성: LSTM 모델에 적합한 형태로 데이터를 변환합니다.
- LSTM 모델 구축: 두 개의 LSTM 레이어와 하나의 출력 레이어로 구성된 모델을 정의합니다.
- 모델 학습 및 예측: 모델을 학습시키고, 테스트 데이터에 대해 예측을 수행합니다.
- 결과 시각화: 실제 주가와 예측 결과를 그래프로 비교하여 시각적으로 확인합니다.
결과에 대한 설명
- DataFrame 출력: 불러온 데이터는 삼성전자의 시가, 고가, 저가, 종가, 거래량 등의 정보를 포함합니다.
- 정규화된 데이터: 정규화된 시가 데이터는 0과 1 사이의 값으로 변환됩니다.
- 예측 결과: LSTM 모델이 예측한 주가가 출력되며, 이를 실제 주가와 비교하여 얼마나 잘 예측했는지를 시각적으로 확인할 수 있습니다. 그래프에서 파란색은 실제 주가, 빨간색은 예측한 주가를 나타냅니다.
FaceDetecter
import cv2
import numpy as np
from matplotlib import pyplot as plt
import keras
# 얼굴 이미지를 저장할 리스트 초기화
face_images = list()
# 1부터 15까지의 이미지 파일을 읽어와서 리스트에 추가
for i in range(15):
file = './faces/' + 'img{0:02d}.jpg'.format(i + 1) # 파일 경로 설정
img = cv2.imread(file) # 이미지 읽기
img = cv2.resize(img, (64, 64)) # 이미지 크기 조정
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # BGR에서 RGB로 변환
face_images.append((img)) # 리스트에 이미지 추가
# 이미지를 출력하는 함수 정의
def plot_images(n_row: int, n_col: int, image: list[np.array]) -> None:
fig = plt.figure()
(fig, ax) = plt.subplots(n_row, n_col, figsize=(n_col, n_row))
for i in range(n_row):
for j in range(n_col):
if n_row <= 1:
axis = ax[j]
else:
axis = ax[i, j]
axis.get_xaxis().set_visible(False) # x축 숨기기
axis.get_yaxis().set_visible(False) # y축 숨기기
axis.imshow(image[i * n_col + j]) # 이미지를 축에 표시
plt.show() # 이미지를 화면에 출력
return None
# 얼굴 이미지를 출력
plot_images(n_row=3, n_col=5, image=face_images)
# 동물 이미지를 저장할 리스트 초기화
animal_images = []
# 1부터 15까지의 이미지 파일을 읽어와서 리스트에 추가
for i in range(15):
file = './animals/' + 'img{0:02d}.jpg'.format(i + 1) # 파일 경로 설정
img = cv2.imread(file) # 이미지 읽기
img = cv2.resize(img, (64, 64)) # 이미지 크기 조정
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # BGR에서 RGB로 변환
animal_images.append((img)) # 리스트에 이미지 추가
# 동물 이미지를 출력
plot_images(n_row=3, n_col=5, image=animal_images)
# 학습할 데이터와 정답 데이터 생성
X = face_images + animal_images # 두 리스트를 합쳐서 입력 데이터 생성
y = [[1, 0]] * len(face_images) + [[0, 1]] * len(animal_images) # 얼굴은 [1, 0], 동물은 [0, 1]로 레이블 생성
X = np.array(X) # 입력 데이터를 numpy 배열로 변환
y = np.array(y) # 레이블 데이터를 numpy 배열로 변환
print(y) # 레이블 출력
print(y.shape) # 레이블 배열의 형태 출력
# CNN 모델 구축
model = keras.models.Sequential([
keras.Input(shape=(64, 64, 3)), # 입력 이미지 크기 설정
keras.layers.Conv2D(filters=32, kernel_size=(3, 3)), # 첫 번째 합성곱 층
keras.layers.MaxPool2D(pool_size=(2, 2), strides=2), # 첫 번째 풀링 층
keras.layers.Conv2D(filters=32, kernel_size=(3, 3)), # 두 번째 합성곱 층
keras.layers.MaxPool2D(pool_size=(2, 2), strides=2), # 두 번째 풀링 층
keras.layers.Conv2D(filters=32, kernel_size=(3, 3)), # 세 번째 합성곱 층
keras.layers.MaxPool2D(pool_size=(2, 2), strides=2), # 세 번째 풀링 층
keras.layers.Conv2D(filters=32, kernel_size=(3, 3)), # 네 번째 합성곱 층
keras.layers.MaxPool2D(pool_size=(2, 2), strides=2), # 네 번째 풀링 층
keras.layers.Flatten(), # 다차원 배열을 1차원으로 변환
keras.layers.Dense(units=128, activation='relu', name="LAYER1"), # 첫 번째 밀집층
keras.layers.Dense(units=32, activation='relu', name="LAYER2"), # 두 번째 밀집층
keras.layers.Dense(units=2, activation='softmax', name="OUTPUT") # 출력층 (이진 분류)
], name='FACE_CNN')
model.summary() # 모델 구조 요약 출력
model.compile(optimizer="adam", loss='categorical_crossentropy', metrics=['accuracy']) # 모델 컴파일
# 모델 학습
history = model.fit(x=X, y=y, epochs=1_000)
model.save('FACE_DETECTOR.keras') # 모델 저장
# 성능 테스트: 예제 파일을 읽어 이미지 테스트하기
example_images = list()
# 1부터 10까지의 예제 이미지 파일을 읽어와서 리스트에 추가
for i in range(10):
file = './examples/' + 'img{0:02d}.jpg'.format(i + 1) # 파일 경로 설정
img = cv2.imread(file) # 이미지 읽기
img = cv2.resize(img, (64, 64)) # 이미지 크기 조정
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # BGR에서 RGB로 변환
example_images.append((img)) # 리스트에 이미지 추가
# 예제 이미지를 출력
example_images = np.array(example_images) # numpy 배열로 변환
plot_images(n_col=5, n_row=2, image=example_images)
# 저장된 모델 불러오기
model2 = keras.models.load_model('FACE_DETECTOR.keras')
# 예제 이미지에 대한 예측 수행
predict_images = model2.predict(x=example_images)
print(np.round(predict_images)) # 예측 결과 출력
# 예측 결과 시각화
(fig, ax) = plt.subplots(2, 5, figsize=(10, 4))
for i in range(2):
for j in range(5):
axis = ax[i, j]
axis.get_xaxis().set_visible(False) # x축 숨기기
axis.get_yaxis().set_visible(False) # y축 숨기기
if predict_images[i * 5 + j][0] > 0.5: # 예측 결과가 0.5보다 크면 얼굴로 판단
axis.imshow(example_images[i * 5 + j]) # 이미지를 축에 표시
plt.show() # 결과 출력- 이미지 로딩 및 전처리: 얼굴 이미지와 동물 이미지를 각각 읽어와서 크기를 조정하고 색상을 변환한 후 리스트에 저장합니다.
- 이미지 출력: plot_images 함수를 사용하여 로드한 이미지를 행렬 형태로 출력합니다.
- 데이터 및 레이블 생성: 얼굴과 동물 이미지를 합쳐서 입력 데이터 X를 만들고, 각 클래스에 대한 레이블 y를 생성합니다.
- CNN 모델 구축 및 컴파일: 여러 개의 합성곱층과 풀링층을 포함한 CNN 모델을 구축하고, 손실 함수와 옵티마이저를 설정합니다.
- 모델 학습: 주석 처리된 부분에서 모델을 학습하고 저장하는 코드가 있습니다.
- 예제 이미지 로딩 및 예측: 예제 이미지를 로드하여 모델을 사용해 예측을 수행합니다.
- 예측 결과 시각화: 예측 결과를 바탕으로 0.5 이상의 확률을 가진 이미지만 출력합니다.
결과
- 모델이 학습된 후, 새로운 예제 이미지에 대해 얼굴과 동물 이미지를 구분할 수 있는지 테스트합니다.
- 예측 결과는 신뢰도에 따라 0 또는 1로 표시되며, 신뢰도가 0.5 이상인 이미지만 화면에 출력됩니다.
- 이 코드는 얼굴 이미지와 동물 이미지를 성공적으로 구분할 수 있는 간단한 CNN 모델의 예시입니다. 사용자가 제공한 이미지 데이터의 품질과 양에 따라 모델의 성능이 달라질 수 있습니다.




'ABC 부트캠프 데이터 탐험가 4기' 카테고리의 다른 글
| [26 일] ABC 부트캠프 : 머신러닝 팀 프로젝트 (2) (0) | 2024.08.08 |
|---|---|
| [25 일차] ABC 부트캠프 : 머신러닝 팀 프로젝트(1) (0) | 2024.08.07 |
| [23 일차] ABC 부트캠프 : 머신러닝 (5) Code18~Code20 (0) | 2024.08.05 |
| [22 일차] ABC 부트캠프 : 머신러닝 (4) Code12~Code17 (0) | 2024.08.02 |
| [21 일차] ABC 부트캠프 : ESG (3) (0) | 2024.08.02 |