Code03
import matplotlib.pyplot as plt # 데이터 시각화를 위한 matplotlib 라이브러리 임포트
from sklearn import linear_model # 선형 회귀 모델을 사용하기 위한 sklearn 라이브러리 임포트
# Linear Regression 모델 생성
reg = linear_model.LinearRegression() # 선형 회귀 모델 객체 생성
# 입력 데이터 (X)와 출력 데이터 (y) 정의
X = [[0], [1], [2]] # 입력 데이터: 0, 1, 2
y = [3, 3.5, 5.5] # 출력 데이터: 각 입력에 대한 출력 값
reg.fit(X, y) # 입력 데이터와 출력 데이터를 사용하여 모델 학습
print(reg.score(X, y)) # 모델의 결정 계수(R^2)를 출력하여 모델 성능 평가
print(reg.coef_) # 학습된 선형 회귀 모델의 기울기(회귀 계수)를 출력
print(reg.intercept_) # 회귀 모델의 절편을 출력
print(reg.predict(X=[[5]])) # 입력값 5에 대한 예측 결과를 출력
plt.scatter(x=X, y=y, color='red') # 입력 데이터와 출력 데이터를 산점도로 시각화 (붉은 점으로 표시)
plt.show() # 시각화된 그래프를 화면에 표시
y_predict = reg.predict(X) # 입력 데이터에 대한 예측 값을 계산
plt.plot(X, y_predict, color='blue', linewidth=2) # 예측된 선형 회귀 직선을 파란색으로 시각화
plt.show() # 시각화된 그래프를 화면에 표시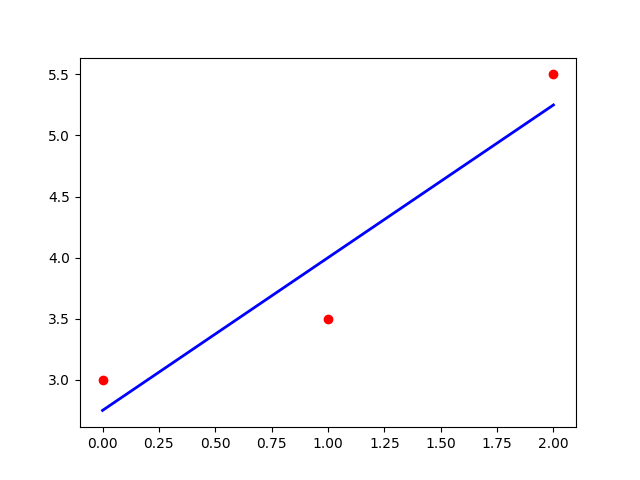

간단한 선형 회귀 모델을 생성하고, 주어진 입력 데이터와 출력 데이터에 대해 모델을 학습하는 과정을 보여줍니다.
- 데이터 준비: 입력 데이터 X와 출력 데이터 y를 정의합니다.
- 모델 학습: fit 메서드를 사용하여 모델을 학습합니다.
- 모델 평가: 결정 계수(R²), 회귀 계수(기울기), 절편을 출력하여 모델의 성능을 평가합니다.
- 예측: 입력값 5에 대한 예측 결과를 출력합니다.
- 시각화: 입력 데이터와 출력 데이터를 산점도로 표시하고, 학습된 선형 회귀 모델의 예측 직선을 그립니다.
결과적으로 주어진 데이터에 대한 선형 회귀 분석을 수행하고, 그 결과를 시각화하여 보여줍니다.
Code04
import pandas as pd # 데이터 처리를 위한 pandas 라이브러리 임포트
# CSV 파일에서 와인 데이터를 읽어옴
wine = pd.read_csv(filepath_or_buffer="wine_csv_data.csv")
print(wine) # 전체 데이터 출력
print(wine.head()) # 데이터의 첫 5행 출력
print(wine.shape) # 데이터의 행과 열의 수 출력
print(wine.info()) # 데이터의 정보(열의 데이터 타입과 결측치 등) 출력
# 'alcohol', 'sugar', 'pH' 열을 선택하여 numpy 배열로 변환
data = wine[['alcohol', 'sugar', 'pH']].to_numpy()
print(data) # 변환된 데이터 출력
print(data.shape) # 변환된 데이터의 형태 출력
target = wine['class'].to_numpy() # 'class' 열을 정답(target)으로 설정
print(target) # 정답 데이터 출력
print(target.shape) # 정답 데이터의 형태 출력
from sklearn.model_selection import train_test_split # 데이터 분할을 위한 함수 임포트
from sklearn.linear_model import LogisticRegression # 로지스틱 회귀 모델 임포트
# 데이터와 타겟 정의 (예시)
data = ... # 입력 데이터 (위에서 정의된 data)
target = ... # 타겟 데이터 (위에서 정의된 target)
# 데이터 분할: 80%는 훈련용, 20%는 테스트용
X_train, X_test, y_train, y_test = train_test_split(data, target, test_size=0.2)
# 로지스틱 회귀 모델 생성
lr = LogisticRegression()
# 모델 학습: 훈련 데이터를 사용하여 모델을 학습
lr.fit(X_train, y_train)
# 훈련 세트와 테스트 세트의 정확도 출력
print(lr.score(X_train, y_train)) # 훈련 세트에 대한 정확도 출력
print(lr.score(X_test, y_test)) # 테스트 세트에 대한 정확도 출력
print(lr.coef_) # 학습된 모델의 회귀 계수 출력
print(lr.intercept_) # 학습된 모델의 절편 출력

와인 데이터셋을 로드하고, 로지스틱 회귀 모델을 사용하여 주어진 데이터를 학습하고 평가하는 과정을 보여줍니다.
- 데이터 로드 및 탐색: CSV 파일에서 데이터를 읽어오고, 데이터의 기본 정보와 구조를 출력합니다.
- 데이터 전처리: 특정 열(alcohol, sugar, pH)을 선택하여 입력 데이터로 사용하고, class 열을 타겟 데이터로 설정합니다.
- 데이터 분할: train_test_split 함수를 사용하여 데이터를 훈련 세트와 테스트 세트로 분할합니다.
- 모델 생성 및 학습: 로지스틱 회귀 모델을 생성하고, 훈련 데이터를 사용하여 모델을 학습합니다.
- 모델 평가: 훈련 세트와 테스트 세트의 정확도를 출력하고, 모델의 회귀 계수와 절편을 확인합니다.
결과적으로 와인 데이터에 대한 로지스틱 회귀 분석을 수행하고, 모델의 성능을 평가하는 과정을 포함합니다.
Code05
import numpy as np # 수치 계산을 위한 numpy 라이브러리 임포트
from sklearn.linear_model import LinearRegression # 선형 회귀 모델 임포트
from sklearn.datasets import load_iris # 아이리스 데이터셋 로드 함수 임포트
# 아이리스 데이터셋 로드
iris = load_iris()
print(iris) # 아이리스 데이터셋의 전체 정보 출력
print(type(iris)) # iris 객체의 타입 출력
print(iris.data) # 아이리스 데이터셋의 특성 데이터 출력
print(type(iris.data)) # iris.data의 타입 출력
print('-' * 50)
# 특성과 타겟 데이터 정의
data = iris.data # 입력 데이터(특성)
target = iris.target # 타겟 데이터(클래스)
print(target) # 타겟 데이터 출력
print(type(target)) # target의 타입 출력
print(target.shape) # target의 형태 출력
print('-' * 50)
from sklearn.model_selection import train_test_split # 데이터 분할 함수 임포트
# 데이터셋을 훈련 세트와 테스트 세트로 분할 (80% 훈련, 20% 테스트)
(X_train, X_test, Y_train, Y_test) = train_test_split(data, target, train_size=0.8)
print(X_train.shape) # 훈련 세트의 형태 출력
print(X_test.shape) # 테스트 세트의 형태 출력
# 머신러닝 모델 선택하기
regression = LinearRegression() # 선형 회귀 모델 객체 생성
# 훈련시키기
regression.fit(X_train, Y_train) # 훈련 데이터를 사용하여 모델 학습
print('-' * 50)
print(f'Weight : {regression.coef_}') # 학습된 모델의 회귀 계수(가중치) 출력
print(f'Bias : {regression.intercept_}') # 학습된 모델의 절편 출력
print(regression.score(X_train, Y_train)) # 훈련 세트에 대한 모델의 정확도 출력
# 테스트 세트를 사용하여 예측 수행
Y_predicts = regression.predict(X_test) # 테스트 데이터에 대한 예측 결과
print('-' * 50) # 주석 처리된 구분선 출력
print(Y_predicts) # 예측 결과 출력
print(Y_predicts.shape) # 예측 결과의 형태 출력
print(Y_test) # 정답 데이터 출력
print('-' * 50)
# 예측 결과를 반올림하여 정수형으로 변환
print(np.round(Y_predicts).astype(int)) # 반올림된 예측 결과 출력
print(Y_test) # 실제 정답 데이터 출력
rounded_Y_predicts = np.round(Y_predicts).astype(int) # 반올림된 예측 결과 저장
from matplotlib import pyplot as plt # 데이터 시각화를 위한 matplotlib 라이브러리 임포트
plt.plot(rounded_Y_predicts, Y_test, '*') # 예측 결과와 실제 정답을 별표로 시각화
plt.show() # 시각화된 그래프를 화면에 표시

아이리스 데이터셋을 사용하여 선형 회귀 모델을 학습하고, 예측 결과를 평가하는 과정을 보여줍니다.
- 데이터 로드: 아이리스 데이터셋을 로드하고, 데이터의 기본 정보와 구조를 출력합니다.
- 데이터 전처리: 특성과 타겟 데이터를 정의합니다.
- 데이터 분할: train_test_split 함수를 사용하여 데이터를 훈련 세트와 테스트 세트로 분할합니다.
- 모델 생성 및 학습: 선형 회귀 모델을 생성하고, 훈련 데이터를 사용하여 모델을 학습합니다.
- 모델 평가: 학습된 모델의 회귀 계수와 절편을 출력하고, 훈련 세트에 대한 정확도를 평가합니다.
- 예측 수행: 테스트 세트를 사용하여 예측 결과를 생성하고, 이를 반올림하여 정수형으로 변환합니다.
- 시각화: 예측 결과와 실제 정답을 시각화하여 비교합니다.
결과적으로 아이리스 데이터에 대한 선형 회귀 분석을 수행하고, 모델의 성능을 시각적으로 평가하는 과정을 포함합니다.
'ABC 부트캠프 데이터 탐험가 4기' 카테고리의 다른 글
| [21 일차] ABC 부트캠프 : ESG (3) (0) | 2024.08.02 |
|---|---|
| [20 일차] ABC 부트캠프 : 머신러닝 (3) Code06~Code11 (0) | 2024.07.31 |
| [18 일차] ABC 부트캠프 : 머신러닝 (1) Code01~Code02 (0) | 2024.07.31 |
| [17 일차] ABC 부트캠프 : 건양대학교 견학 (0) | 2024.07.28 |
| [16 일차] ABC 부트캠프 : 데이터 분석 팀 프로젝트 (0) | 2024.07.28 |