베스트셀러로 알아보는 시대별 기술 및 컴퓨터 분야 트랜드
패키지 설치 및 임포트
!pip install konlpy !pip install koreanize-matplotlib import pandas as pd import numpy as np import konlpy import matplotlib.pyplot as plt import koreanize_matplotlib import plotly.express as px import re from plotly.subplots import make_subplots from collections import Counter from PIL import Image from wordcloud import WordCloud, ImageColorGenerator import plotly.graph_objs as go
2008~2023년 데이터
전처리 및 키워드 분류
file_paths = [ "/content/교보문고_2008년_top50_20240724.csv", "/content/교보문고_2009년_top50_20240724.csv", "/content/교보문고_2010년_top50_20240724.csv", "/content/교보문고_2011년_top50_20240724.csv", "/content/교보문고_2012년_top50_20240724.csv", "/content/교보문고_2013년_top50_20240724.csv", "/content/교보문고_2014년_top50_20240724.csv", "/content/교보문고_2015년_top50_20240724.csv", "/content/교보문고_2016년_top50_20240724.csv", "/content/교보문고_2017년_top50_20240724.csv", "/content/교보문고_2018년_top50_20240724.csv", "/content/교보문고_2019년_top50_20240724.csv", "/content/교보문고_2020년_top50_20240724.csv", "/content/교보문고_2021년_top50_20240724.csv", "/content/교보문고_2022년_top50_20240724.csv", "/content/교보문고_2023년_top50_20240724.csv",] # 연도를 추출하는 함수 def extract_year(filename): match = re.search(r'\d{4}', filename) if match: return match.group(0) return None # 데이터프레임 리스트에 각 파일 데이터를 저장 및 연도 추가 dataframes = [] for path in file_paths: df = pd.read_csv(path) year = extract_year(path) df['출판연도'] = year dataframes.append(df) # 데이터 프레임 병합 merged_df = pd.concat(dataframes, ignore_index=True) # 태그 열이 문자열인지 확인하고, 그렇지 않은 경우는 빈 문자열로 처리 merged_df['태그'] = merged_df['태그'].astype(str).fillna('') keywords = { '기술 분야': [ '데이터베이스', '웹', 'UI/UX 디자인', '인공지능', '머신러닝', '딥러닝', '빅데이터', '클라우드 컴퓨팅', '사물인터넷', 'IoT', '블록체인', '사이버 보안', '네트워크', '운영체제', '컴퓨터 과학', '소프트웨어 엔지니어링', '로봇공학' ], '프로그래밍 언어': [ 'Python', 'Java', 'C++', 'JavaScript', 'R', 'C', 'C#', 'PHP', 'Swift', 'Kotlin', 'Go', 'Ruby', 'Perl', 'Scala', 'Rust', 'Dart', 'MATLAB', 'SQL', 'HTML', 'CSS', 'TypeScript', 'Bash', 'PowerShell' ], '멀티미디어': [ '멀티미디어', '비디오 편집', '오디오', '영상 제작', '애니메이션', '3D 모델링', '디지털 아트', '사진 편집', '팟캐스트', 'VFX','그래픽 디자인' ], '스마트폰': ['모바일프로그래밍','스마트폰/태블릿','아이폰/아이패드','안드로이드'] }
각 분야별 트렌드 그래프# 키워드를 기반으로 새로운 열 추가 for category, words in keywords.items(): merged_df[category] = merged_df['태그'].apply(lambda x: any(word in x for word in words)) # 연도별로 그룹화하여 각 카테고리별 도서 수를 집계 yearly_trends = merged_df.groupby(merged_df['출판연도']).sum(numeric_only=True) # 그래프 그리기 fig = px.line(yearly_trends.drop(columns=['순위']), x=yearly_trends.index, y=yearly_trends.drop(columns=['순위']).columns, title='연도별 기술 및 컴퓨터 분야 도서 트렌드', labels={'value': '도서 수', 'variable': '카테고리'}) fig.update_layout(xaxis_title='연도', yaxis_title='도서 수') fig.show()
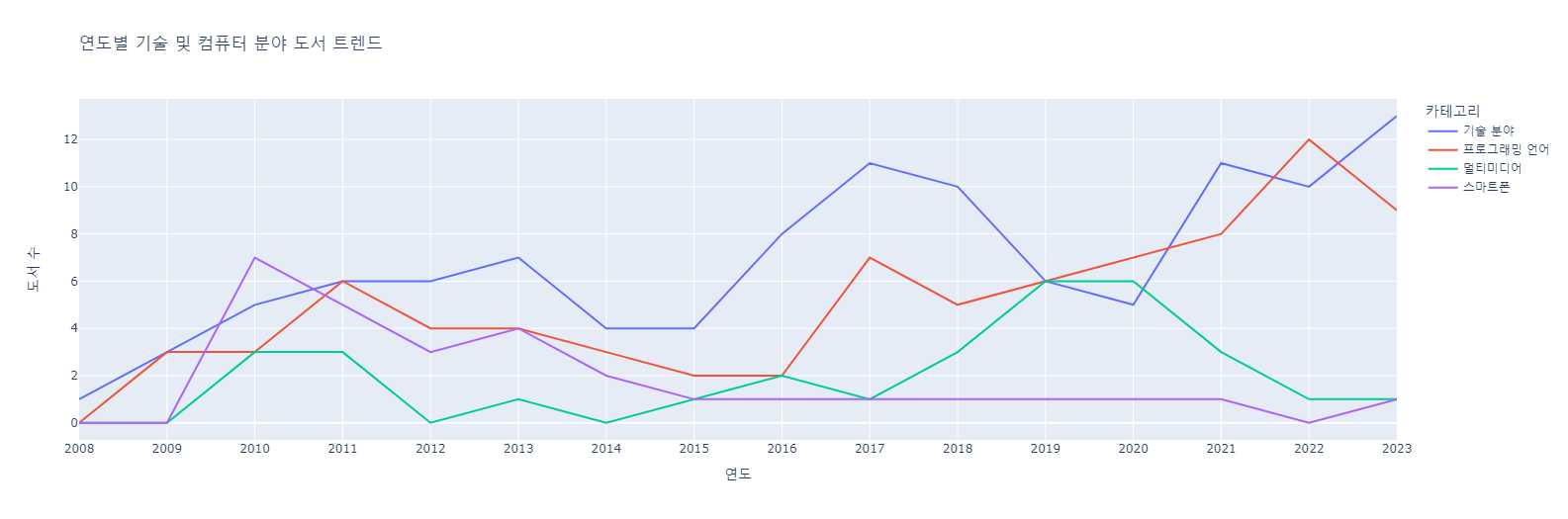
프로그래밍 언어 트렌드 그래프
# 'programming 분야'에 해당하는 데이터만 필터링
programming_df = merged_df.copy()
# '프로그래밍 언어' 관련 키워드 설정
programming_languages = [
'Python', 'Java', 'JavaScript', 'C']
# 카테고리별 도서 수를 집계할 새로운 데이터프레임 생성
category_trends = pd.DataFrame()
# 각 카테고리에 해당하는 키워드로 데이터 분류 및 집계
for language in programming_languages:
programming_df[language] = programming_df['태그'].apply(lambda x: language in x)
category_count = programming_df.groupby('출판연도')[language].sum()
category_trends[language] = category_count
# 데이터프레임을 길게 변환하여 plotly express에 적합하게 변환
category_trends = category_trends.reset_index().melt(id_vars='출판연도', var_name='언어', value_name='도서 수')
# 막대 그래프 그리기 (누적)
fig = px.bar(category_trends, x='출판연도', y='도서 수', color='언어', text='도서 수', title='연도별 프로그래밍 언어 도서 트렌드')
fig.update_layout(xaxis_title='연도', yaxis_title='도서 수', barmode='stack')
# 그래프 보여주기
fig.show()
기술 분야 트렌드 그래프
# '기술 분야'에 해당하는 데이터만 필터링
tech_df = merged_df.copy()
# '기술 분야' 관련 키워드 설정
tech_categories = [ '웹',
'인공지능', '머신러닝', '딥러닝', '빅데이터',
'블록체인']
# 카테고리별 도서 수를 집계할 새로운 데이터프레임 생성
category_trends = pd.DataFrame()
# 각 카테고리에 해당하는 키워드로 데이터 분류 및 집계
for language in tech_categories:
tech_df[language] = tech_df['태그'].apply(lambda x: language in x)
category_count = tech_df.groupby('출판연도')[language].sum()
category_trends[language] = category_count
# 데이터프레임을 길게 변환하여 plotly express에 적합하게 변환
category_trends = category_trends.reset_index().melt(id_vars='출판연도', var_name='언어', value_name='도서 수')
# 막대 그래프 그리기 (x축과 y축 값 교환)
fig = px.bar(category_trends,
x='도서 수', # 원래 y축이었던 '도서 수'를 x축으로
y='출판연도', # 원래 x축이었던 '출판연도'를 y축으로
color='언어',
text='도서 수', # 막대 옆에 도서 수를 텍스트로 표시
title='연도별 기술 분야 도서 트렌드')
# 텍스트 회전 설정
fig.update_traces(textangle=0) # 텍스트를 90도 회전
# 레이아웃 업데이트
fig.update_layout(xaxis_title='도서 수', yaxis_title='출판연도')
# 그래프 표시
fig.show()
기업별 채용인력 변화 + it 기업의 증가 폭 그래프
# 데이터 준비
data1 = {
'현재인원': [2012, 2013, 2014, 2015, 2016, 2017, 2018, 2019, 2020, 2021, 2022],
'소프트웨어': [117746, 121786, 124277, 128641, 130265, 135872, 139454, 142914, 146714, 148270, 150122],
'반도체': [85899, 88572, 91113, 90492, 86525, 90501, 92873, 95429, 99285, 104004, 109014]
}
data2 = {
'프로그래밍 기업수': [2011, 2012, 2013, 2014, 2015, 2016, 2017, 2018, 2019, 2020, 2021, 2022],
'활동기업': [11765, 12377, 13121, 13997, 14866, 15987, 17454, 18899, 20217, 22167, 24754, 26942],
'신생기업': [2197, 2365, 2374, 2656, 2594, 2829, 3202, 3342, 3432, 3973, 4597, 4547]
}
# 데이터프레임으로 변환
df1 = pd.DataFrame(data1)
df2 = pd.DataFrame(data2)
# 두 개의 y축을 사용하여 그래프 그리기
fig, ax1 = plt.subplots(figsize=(12, 6))
# 첫 번째 y축: 소프트웨어 및 반도체
ax1.set_xlabel('연도', fontsize=12)
ax1.set_ylabel('현재인원 (천명)', fontsize=12, color='tab:blue')
ax1.plot(df1['현재인원'], df1['소프트웨어'], marker='o', linestyle='-', color='tab:blue', label='소프트웨어')
ax1.plot(df1['현재인원'], df1['반도체'], marker='s', linestyle='--', color='tab:green', label='반도체')
ax1.tick_params(axis='y', labelcolor='tab:blue')
ax1.set_ylim(80000, 160000)
# 두 번째 y축: 활동기업 및 신생기업
ax2 = ax1.twinx()
ax2.set_ylabel('기업 수 (천개)', fontsize=12, color='tab:orange')
ax2.bar(df2['프로그래밍 기업수'] - 0.15, df2['활동기업'], width=0.3, color='tab:orange', alpha=0.6, label='활동기업')
ax2.bar(df2['프로그래밍 기업수'] + 0.15, df2['신생기업'], width=0.3, color='tab:red', alpha=0.6, label='신생기업')
ax2.tick_params(axis='y', labelcolor='tab:orange')
ax2.set_ylim(0, 30000)
# 범례 설정
fig.legend(loc='upper left', bbox_to_anchor=(0.1, 0.9), bbox_transform=ax1.transAxes)
# 그래프 제목과 레이블 설정
plt.title('산업별 현재 근무인원 및 프로그래밍 기업수', fontsize=14)
fig.tight_layout() # 레이아웃 최적화
plt.grid(True, which='both', linestyle='--', linewidth=0.5, alpha=0.7)
plt.show()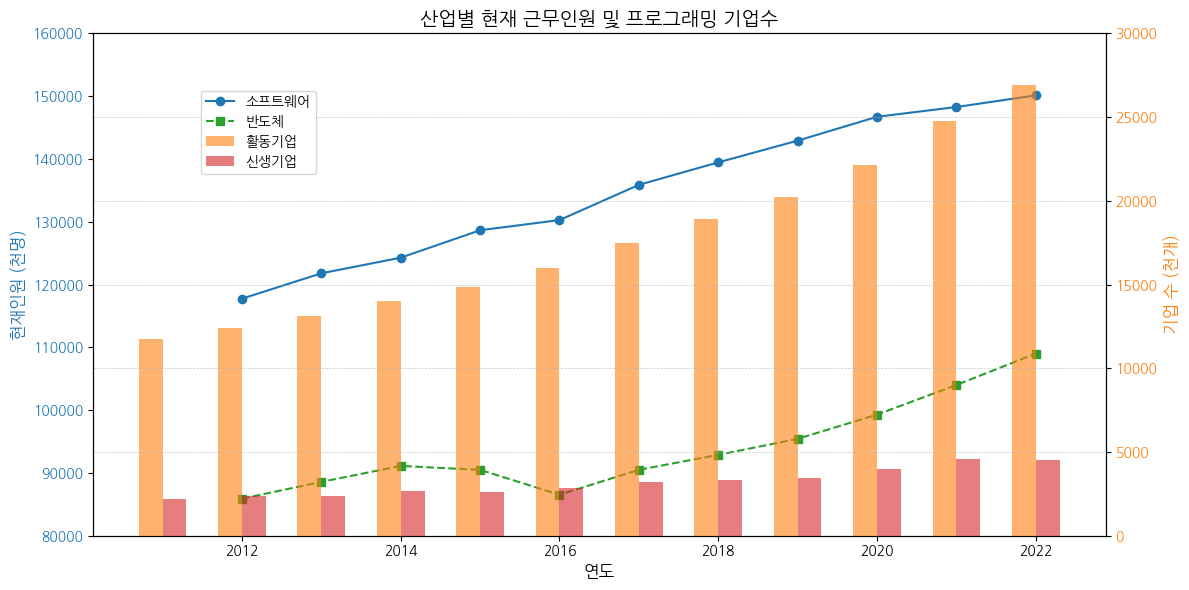
2024년 1~6월 데이터 수집 및 전처리
file_paths2 = ['/content/교보문고_2024년_1월_top50_20240725.csv',
'/content/교보문고_2024년_2월_top50_20240725.csv',
'/content/교보문고_2024년_3월_top50_20240725.csv',
'/content/교보문고_4년_top50_20240725.csv',
'/content/교보문고_5년_top50_20240725.csv',
'/content/교보문고_6년_top50_20240725.csv']
# 연도를 추출하는 함수
def extract_year(filename):
match = re.search(r'\d{4}', filename)
if match:
return match.group(0)
return None
# 데이터프레임 리스트에 각 파일 데이터를 저장 및 연도 추가
dataframes = []
for path in file_paths2:
df = pd.read_csv(path)
year = extract_year(path)
df['출판연도'] = year
dataframes.append(df)
# 데이터 프레임 병합
merged_df = pd.concat(dataframes, ignore_index=True)
# 태그 열이 문자열인지 확인하고, 그렇지 않은 경우는 빈 문자열로 처리
merged_df['태그'] = merged_df['태그'].astype(str).fillna('')
keywords = {
'기술 분야': [
'데이터베이스', '웹',
'UI/UX 디자인', '인공지능', '머신러닝', '딥러닝', '빅데이터',
'클라우드 컴퓨팅', '사물인터넷', 'IoT', '블록체인', '사이버 보안',
'네트워크', '운영체제', '컴퓨터 과학', '소프트웨어 엔지니어링', '로봇공학'
],
'프로그래밍 언어': [
'Python', 'Java', 'C++', 'JavaScript', 'R', 'C', 'C#', 'PHP',
'Swift', 'Kotlin', 'Go', 'Ruby', 'Perl', 'Scala', 'Rust', 'Dart',
'MATLAB', 'SQL', 'HTML', 'CSS', 'TypeScript', 'Bash', 'PowerShell'
],
'멀티미디어': [
'멀티미디어', '비디오 편집', '오디오', '영상 제작', '애니메이션',
'3D 모델링', '디지털 아트', '사진 편집', '팟캐스트', 'VFX','그래픽 디자인'
]
}
2024 데이터 월별 키워드 수 정리
# 월별 키워드 카운트를 저장할 데이터프레임 초기화
monthly_counts = pd.DataFrame(columns=['월', '기술 분야', '프로그래밍 언어', '멀티미디어'])
# 각 파일 처리
for i, file_path in enumerate(file_paths2):
# CSV 파일 읽기
df = pd.read_csv(file_path)
# 각 카테고리별 키워드 개수 초기화
tech_count = 0
prog_count = 0
media_count = 0
# 태그 열에서 키워드 개수 세기
for tag in df['태그']:
for category, words in keywords.items():
for word in words:
if word in tag:
if category == '기술 분야':
tech_count += 1
elif category == '프로그래밍 언어':
prog_count += 1
elif category == '멀티미디어':
media_count += 1
# 월 저장
month = i + 1
# 새로운 데이터프레임 생성
new_row = pd.DataFrame({
'월': [month],
'기술 분야': [tech_count],
'프로그래밍 언어': [prog_count],
'멀티미디어': [media_count]
})
# 기존 데이터프레임과 새로운 데이터프레임 결합
monthly_counts = pd.concat([monthly_counts, new_row], ignore_index=True)
# 그래프 그리기
monthly_counts.set_index('월').plot(kind='bar', stacked=True)
plt.title('월별 키워드 수')
plt.xlabel('월')
plt.ylabel('키워드 수')
plt.xticks(rotation=0)
plt.legend(title='카테고리')
plt.tight_layout()
plt.show()
기술 분야, 프로그래밍 언어, 멀티미디어 키워드 수 정리
for category in ['기술 분야', '프로그래밍 언어', '멀티미디어']:
plt.plot(monthly_counts['월'], monthly_counts[category], marker='o', label=category)
plt.title('월별 키워드 수')
plt.xlabel('월')
plt.ylabel('키워드 수')
plt.xticks(rotation=0)
plt.legend(title='카테고리')
plt.tight_layout()
plt.show()
기술 분야 키워드 정리
# 기술 분야 키워드
tech_keywords = [
'데이터베이스', '웹', 'UI/UX 디자인', '인공지능', '머신러닝',
'딥러닝', '빅데이터', '클라우드 컴퓨팅', '사물인터넷',
'IoT', '블록체인', '사이버 보안', '운영체제',
'컴퓨터 과학', '소프트웨어 엔지니어링', '로봇공학'
]
# 월별 기술 분야 키워드 카운트를 저장할 데이터프레임 초기화
tech_monthly_counts = pd.DataFrame(columns=['월'] + tech_keywords)
# 각 파일 처리
for i, file_path in enumerate(file_paths2):
# CSV 파일 읽기
df = pd.read_csv(file_path)
# 월별 키워드 카운트 초기화
keyword_counts = {keyword: 0 for keyword in tech_keywords}
# 태그 열에서 기술 분야 키워드 개수 세기
for tag in df['태그']:
for keyword in tech_keywords:
if keyword in tag:
keyword_counts[keyword] += 1
# 월 저장
month = i + 1
# 새로운 데이터프레임 생성
new_row = {'월': month}
new_row.update(keyword_counts)
# 기존 데이터프레임과 새로운 데이터프레임 결합
tech_monthly_counts = pd.concat([tech_monthly_counts, pd.DataFrame([new_row])], ignore_index=True)
# 꺽은선 그래프 그리기
plt.figure(figsize=(12, 8))
# 키워드가 1 이상인 경우에만 그래프에 추가
for keyword in tech_keywords:
if tech_monthly_counts[keyword].sum() > 0: # 해당 키워드의 총합이 0보다 큰 경우
plt.plot(tech_monthly_counts['월'], tech_monthly_counts[keyword], marker='o', label=keyword)
plt.title('월별 기술 분야 키워드 수')
plt.xlabel('월')
plt.ylabel('키워드 수')
plt.xticks(rotation=0)
plt.grid()
plt.legend(title='기술 분야 키워드', bbox_to_anchor=(1.05, 1), loc='upper left')
plt.tight_layout()
plt.show()
'ABC 부트캠프 데이터 탐험가 4기' 카테고리의 다른 글
| [18 일차] ABC 부트캠프 : 머신러닝 (1) Code01~Code02 (0) | 2024.07.31 |
|---|---|
| [17 일차] ABC 부트캠프 : 건양대학교 견학 (0) | 2024.07.28 |
| [15 일차] ABC 부트캠프 : 구글 이미지 검색을 활용한 이미지 수 (0) | 2024.07.27 |
| [14 일차] ABC 부트캠프 : 멜론 TOP30 크롤링 및 시각화 (0) | 2024.07.27 |
| [13 일차] ABC 부트캠프 : 네이버 연예 공감별 랭킹 뉴스 크롤링 및 유튜브 댓글 크롤링(동적 크롤링) (4) | 2024.07.23 |